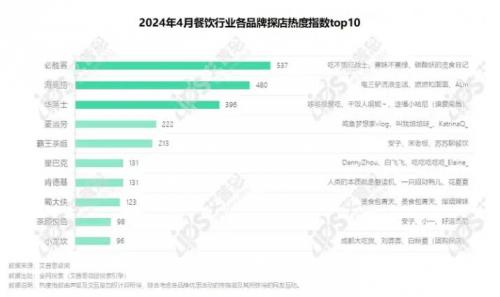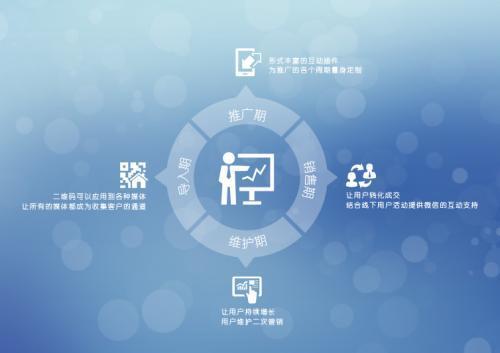
隨著移動互聯網的普及與消費者習慣的深刻變革,傳統餐飲營銷策略正逐漸顯露出其局限性。單純依賴門店位置、傳單發放或傳統廣告的‘坐商’模式,已難以在激烈的市場競爭中脫穎而出。對于餐飲創業者而言,及時洞察趨勢,掌握并擁抱食品互聯網銷售這一新方向,已成為決定成敗的關鍵。
一、傳統營銷之困:成本攀升與觸達失效
傳統的餐飲營銷往往圍繞線下實體展開,其核心痛點日益凸顯。高昂的租金成本限制了黃金地段的布局,傳單的轉化率持續走低且不環保,而電視、廣播等傳統廣告則投入巨大、受眾模糊。更重要的是,這些方式與新一代消費者——他們的生活與決策高度數字化——的連接日漸薄弱。信息過載使得傳統廣告難以留下深刻印象,消費者更傾向于信賴社交媒體推薦、線上評價和親友的數字化分享。
二、食品互聯網銷售:定義新營銷核心
食品互聯網銷售遠不止是‘把食物放到網上賣’。它是一個整合了品牌建設、產品展示、在線交易、互動營銷、數據驅動及物流履約的完整生態系統。其作為新營銷方向的核心優勢在于:
- 精準觸達與無限場景:通過社交媒體平臺(如小紅書、抖音)、外賣平臺、私域社群(微信社群、企業微信)及自建小程序,餐飲品牌可以精準定位目標客群,將營銷信息嵌入消費者的日常生活、娛樂和社交場景中,實現‘隨時隨地’的觸達。
- 內容驅動與品牌人格化:互聯網銷售的本質是內容營銷。通過拍攝精美的菜品圖片、制作后廚故事短視頻、直播烹飪過程、分享食材溯源,餐飲品牌得以構建豐富的故事和獨特的品牌人格。這不僅能激發購買欲,更能建立情感連接和品牌忠誠度。例如,一個專注‘一人食’的便當品牌,通過講述都市獨居青年的飲食關懷故事,便能引發強烈共鳴。
- 數據賦能與科學決策:互聯網銷售平臺提供了寶貴的數據洞察。從瀏覽量、點擊率、轉化率到用戶畫像、復購周期、口味偏好,這些數據幫助創業者實時了解市場反饋,精準調整產品結構、營銷策略及定價模型,實現從‘憑經驗感覺’到‘憑數據決策’的飛躍。
- 渠道融合與體驗延伸:成功的互聯網銷售并非取代堂食,而是與之融合,打造‘堂食+外賣+零售’的全渠道模式。例如,將招牌菜開發成預包裝食品在線銷售,突破門店時空限制;通過線上會員體系反哺線下客流,形成消費閉環。
三、餐飲創業者的關鍵行動指南
要掌握這一新方向,餐飲創業者需系統性布局:
- 構建線上品牌陣地:優先建立并運營好在主流生活平臺(大眾點評、抖音企業號)的官方賬號,并考慮開發品牌小程序或微商城,作為私域流量沉淀和銷售的核心。
- 打造‘可傳播’的產品:產品研發需考慮互聯網屬性,包括外賣包裝的體驗感、適合短視頻展示的視覺沖擊力、以及能否衍生出零售化產品。
- 深耕內容營銷:定期產出高質量圖文、短視頻及直播內容,與用戶互動,鼓勵用戶生成內容(UGC),利用KOL/KOC進行口碑擴散。
- 建立數據化運營體系:學會使用各平臺的數據分析工具,關注關鍵指標,持續優化從流量獲取到訂單轉化的全鏈路效率。
- 重構供應鏈與履約能力:確保產品在互聯網銷售鏈路中的品質穩定與配送時效,這是口碑的基石。
###
傳統營銷的過時,本質是‘以門店為中心’的思維過時。在食品互聯網銷售的新浪潮下,成功的餐飲創業必將轉向‘以用戶為中心’的全渠道、數字化運營。這不僅是銷售渠道的拓展,更是品牌建設、客戶關系管理與商業模式的全面革新。唯有主動擁抱變化,將互聯網基因深植于創業藍圖之中,方能在紅海市場中開辟屬于自己的藍海航線。